
K-Nearest Neighbor, atau KNN, adalah salah satu algoritma supervised machine learning yang sangat populer dan seringkali digunakan untuk menyelesaikan kasus-kasus klasifikasi maupun regresi. Cara kerja dari KNN ini sebenarnya cukup sederhana, yaitu dengan mengidentifikasi “K” atau jumlah tetangga terdekat dari data yang sudah ada kemudian menggunakan sampel tersebut untuk menentukan prediksi nilai regresi ataupun klasifikasi dari data baru. Cara kerja dan metode dari KNN adalah non-parametrik karena algoritma ini tidak membuat asumsi apapun dari distribusi data yang ada, sederhananya KNN menentukan nilai atau kelas dari sebuah data dengan melihat data yang ada di sekitar data tersebut. Meskipun sederhana dan sudah diperkenalkan sejak 1950-an, algoritma ini masih jadi salah satu pilihan yang bisa diandalkan untuk membangun kasus-kasus machine learning, terutama pada dataset yang ukurannya relatif kecil hingga menengah dan sudah cukup bersih.
Untuk dapat memahami lebih dalam apa itu KNN dan bagaimana cara kerjanya, di dalam artikel ini kita akan menulis KNN dari nol menggunakan Python dengan OOP style (well, secara teknis gak dari nol banget juga karena kita masih menggunakan dependensi lain seperti NumPy hahaha). Lalu pada artikel berikutnya, kita akan coba mengimplementasikan algoritma yang sudah kita tulis ini ke dalam sebuah use-case.
Kita akan menulis tiga source code, yaitu base.py, classification.py, dan regression.py, dan kemudian kita inisialisasi di dalam __init__.py. Direktori dari projek ini akan terlihat kurang-lebih seperti berikut:
ml_from_scratch/
│
├── neighbors/
│ ├── __init__.py
│ ├── base.py
│ ├── classification.py
│ └── regression.py
│
└── try_ml_algo_notebooks/
│└── try_knn.ipynb
Inisialisasi Kelas baseKNN
Kita memulai projek kita dengan menulis base.py dimana di dalamnya kita akan menyusun kelas baseKNN. Kelas ini nantinya akan menjadi fondasi yang akan mengatur logika inti dalam perhitungan jarak antar data points dan juga sebagai penyimpanan data training.
import numpy as np
import pandas as pd
# ----- base class knn -----
# ----- handle distance calculation and storage of training data ----
class baseKNN:
def __init__(self, k=3, metric="euclidean", p=2):
"""
Initialized KNN base, default k value it's 3.
Parameters:
- k (int): The number of nearest neighbors
- metric (str): distance metric to use
- p (int): Order the norm untuk minkowski distance. Ignored untuk euclidean dan manhattan.
"""
self.k = k # jumlah neighbors yg akan digunakan untuk prediksi
self.X_train = None # placeholder aja untuk training features
self.y_train = None # placeholder juga untuk training target
self.metric = metric
self.p = p
# *************************************
def fit(self, X, y):
"""
Store the training set, convert to arrays if the are not already
Parameters:
- X (array): The training data features
- y (array): The training data target
"""
# cek input pandas dataframe atau pandas series
if isinstance(X, pd.DataFrame):
X = X.values # convert ke array
if isinstance(y, pd.Series):
y = y.values
self.X_train = np.array(X) if not isinstance(X, np.ndarray) else X # cek dan transform to array
self.y_train = np.array(y) if not isinstance(y, np.ndarray) else y # cek dan transform to array
# *************************************
def _calc_distance(self, x1, x2):
"""
Calculate distance antara 2 data point dengan beberapa pilihan distance metrics.
Default euclidean.
Parameters:
- x1 (array): First data point.
- x2 (array): Second data point.
Returns:
- distance (ndarray): Computed distance.
"""
if self.metric == "euclidean":
return np.sqrt(np.sum((x1-x2) ** 2, axis=1))
elif self.metric == "manhattan":
return np.sum(np.abs(x1-x2), axis=1)
elif self.metric == "minkowski":
return np.sum(np.abs(x1-x2) ** self.p, axis=1) ** (1/self.p)
else:
raise ValueError("Unsupported metric. Choose: euclidean, manhattan, or minkowski only.")
# *************************************
def _get_nearest_neighbors(self, x):
"""
Identify the nearest neighbors of a given data point.
This function will calculates the distance from the given point to all data points in the training set,
and then sort the distance, select the index of the k smallest distance.
Parameters:
- x (array): Data point for which to findthe nearest neighbors.
Returns:
- (array): The labels of the k-nearest neighbors.
"""
distances = self._calc_distance(x, self.X_train) # calculate distance x ke semua X training points
nn_idx = np.argsort(distances)[:self.k]
return self.y_train[nn_idx], distances[nn_idx]
Dengan kode di atas, kita akan melakukan penyimpanan data, menghitung jarak antar data point, dan mengidentifikasi tetangga terdekat dari data point yang ingin diprediksi. Kelas baseKNN ini merupakan superclass yang nantinya akan mewarisi fungsi dan properti ke dalam subclass seperti ke regressionKNN dan classificationKNN.
Adapun salah satu fungsi paling krusial di dalam baseKNN adalah calc_distance yang bertugas untuk menghitung jarak antar data point. Fungsi ini mempunyai beberapa pilihan, naum yang paling umum digunakan adalah euclidean. Euclidean mengukur jarak “langsung” antara dua titik, yang dapat kita bayangkan seperti menghitung panjang dari garis lurus yang menghubungkan dua titik tersebut dalam ruang berdimensi-n. Berikut adalah persamaan untuk menghitung jarak Euclidean:
Di dalam kode kita, hal ini diterjemahkan menjadi:
np.sqrt(np.sum((x1 - x2) ** 2, axis=1))
Kelas regressionKNN
Kelas ini akan mengimplementasikan fungsi untuk menangani kasus-kasus regresi di dalam konteks KNN. Dengan mengextend kelas baseKNN, kelas regressionKNN ini mewarisi semua fungsi dan properti dari superclassnya, termasuk penyimpanan dataset training dan pengaturan parameter seperti jumlah tetangga, metrik perhitungan jarak, dan lain-lain.
from .base import baseKNN
import numpy as np
import pandas as pd
class regressionKNN(baseKNN):
def __init__(self, k=3, metric="euclidean", p=2):
super().__init__(k, metric, p)
# *************************************
def predict(self, X):
"""
Predict the target value for each sample in X
Parameters:
- X (array or dataframe): Input samples; [n_samples, n_features]
Returns:
- predictions (array): Predicted values.
"""
if isinstance(X, pd.DataFrame):
X = X.values
predictions = [] # init empty list to store predictions
for i in X:
# for each sample in X, find its nearest neighbors in the training set
neighbors_labels, _ = self._get_nearest_neighbors(i.reshape(1, -1))
nearest_neighbors, nearest_neighbors_distances = self._get_nearest_neighbors(i)
# calculate the average from the neighbors
predictions.append(np.mean(neighbors_labels))
return np.array(predictions), np.array(nearest_neighbors), np.array(nearest_neighbors_distances)
Di dalam regressionKNN terdapat dua fungsi utama; __init__ dan juga predict. Di dalam fungsi predict, kita melakukan beberapa langkah seperti mengkonversi DataFrame ke array jika input yang kita dapatkan berupada DataFrame, lalu kemudian kita akan melakukan pengulangan ke dalam setiap sampel dengan memanfaatkan _get_nearest_neighbors yang diwarisi dari kelas baseKNN. Setelah itu, kita menghitung rata-rata dari target atau label tetangga terdekat kita dan kemudian menggunakan hasilnya sebagai nilai prediksi yang dikembalikan sebagai output predict.
Kelas classificationKNN
Subclass terakhir yang akan kita tulis dalam projek ini adalah classficationKNN dan kita simpan di dalam script classification.py. Kelas ini nantinya khusus digunakan untuk menyelesaikan kasus-kasus klasifikasi, dimana kita akan memprediksi kategori atau grup dri satu entitas berdasarkan fitur ataupun atributnya. Sama seperti regressionKNN, kelas kita ini juga akan memanfaatkan superclass baseKNN.
from .base import baseKNN
import numpy as np
import pandas as pd
from collections import Counter
class classificationKNN(baseKNN):
def __init__(self, k=3, metric="euclidean", p=2):
super().__init__(k, metric, p)
# *************************************
def predict(self, X):
"""
Predict the class label and probability score for each sample in X
Parameters:
- X (array or dataframe): Input samples; [n_samples, n_features]
Returns:
- predictions (list of dict): Predicted class and their proba score.
"""
if isinstance(X, pd.DataFrame):
X = X.values
predictions = [] # init empty list to store predictions
for i in X:
neighbors_labels, _ = self._get_nearest_neighbors(i.reshape(1, -1))
# count
votes = Counter(neighbors_labels)
majority_vote_class, majority_vote_count = votes.most_common(1)[0]
prob_score = majority_vote_count / self.k
predictions.append(({"class":majority_vote_class, "probability":prob_score}))
return predictions
Di dalam fungsi predict pada classificationKNN, kita melakukan beberapa langkah awal seperti apa yang kita lakukan pada regressionKNN. Yang menjadi pembeda adalah fungsi classificationKNNmenentukan kategori mana yang paling sesuai untuk data point yang ingin kita prediksi dengan menghitung kategori terbanyak dari tetangga-tetangga terdekat dari data point tersebut, sementara itu regressionKNN menghitung nilai rata-rata dari tetangga di sekitar data point yang ingin diprediksi. Selain menghitung kategori dengan majority vote, di dalam fungsi ini kita juga menghitung skor probabilitas dari kategori mayoritas tersebut. Nilai yang dikembalikan dari classficationKNN ini berupa dictionary, dimana kita akan mendapatkan kategori mayoritas dan skor probabilitasnya.
__init__.py
Setelah selesai menulis baseKNN, regressionKNN, dan classificationKNN, kita akan mengelola kode-kode ini di dalam script __init__.py.
from .base import baseKNN
from .classification import classificationKNN
from .regression import regressionKNN
__all__ = [
"baseKNN",
"classificationKNN",
"regressionKNN"
]
Kenapa kita memperlukan script ini? Secara sederhana, sebenarnya ini akan membantu kita untuk nantinya dapat mengakses dan menggunakan baseKNN, regressionKNN, dan juga classificationKNN tanpa perlu tau detail import internal juga struktur direktori dimana kelas-kelas ini disimpan.
Eksperimen dan Pengujian Awal
Di dalam notebook try-knn.ipynb, kita melakukan beberapa eksperimen untuk menguji juga mengimplementasi algoritma KNN yang telah kita tulis dengan menggunakan data dummy. Melalui proses ini, kita akan coba memahami gimana sih KNN yang sudah kita tulis bisa berkerja untuk kasus-kasus seperti regresi maupun klasifikasi, apakah sudah sesuai dengan apa yang kita ekspektasikan atau masih belum memenuhinya. Berikut adalah beberapa eksperimen yang kita lakukan.
Pengujian Awal baseKNN
# import packages
import sys
sys.path.append("../")
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from ml_from_scratch.neighbors import baseKNN, regressionKNN, classificationKNN
# generate sample data
np.random.seed(666)
X_train = np.random.rand(15, 2) * 100 # 15 rows, 2 kolom
y_train = np.arange(15)
display(X_train, y_train)
>>> array([[70.04371219, 84.41866429], [67.65143359, 72.78580572], [95.14579574, 1.2703197 ], [41.35876988, 4.88127938], [ 9.99285613, 50.80663058], [20.02475393, 74.41541688], [19.2892003 , 70.08447522], [29.32281059, 77.44794543], [ 0.51088388, 11.28576536], [11.0953672 , 24.76682287], [ 2.32362992, 72.73211542], [34.0034942 , 19.75031564], [90.91795928, 97.8346985 ], [53.28025441, 25.91318494], [58.38126188, 32.56906529]])
>>> array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
# init base knn
model = baseKNN(k=3, metric="euclidean")
# fit model
model.fit(X_train, y_train)
# set test point
test_point = np.array([[30, 15]])
# find nearest neighbors
nearest_neighbors, nearest_neighbors_distances = model._get_nearest_neighbors(test_point)
display(print(f"calculated nearest distance: {nearest_neighbors_distances}"),
print(f"labels of the nearest neighbors: {nearest_neighbors}"))
>>> calculated nearest distance: [ 6.21236384 15.21217145 21.27853309]
>>> labels of the nearest neighbors: [11 3 9]
Pada tahap awal ini, kita menginisialisasi dan menguji objek baseKNN menggunakan dataset dummy. Kita menentukan jumlah k, metrik jarak, dan kemudian memasukkan dataset ke dalam model untuk menemukan tetangga terdekat dari titik uji. Hasilnya memberikan kita pemahaman tentang bagaimana KNN mencari dan menemukan tetangga terdekat berdasarkan metrik yang diberikan. Dari data point yang menjadi data test, kita mendapatkan jika label 11, 3, dan 9 adalah tiga tetangga terdekat dengan menggunakan metrik euclidean.
Pengujian baseKNN dengan Pandas DataFrame
# generate sample data
np.random.seed(666)
X_train = np.random.rand(15, 2) * 100 # 15 rows, 2 kolom
y_train = np.arange(15)
# build dataframe
data = np.hstack((X_train, y_train.reshape(-1, 1))) # combine x dan y secara horizontal
sample_df = pd.DataFrame(data, columns=["Feature_1", "Feature_2", "Target"])
# display dataframe
sample_df
>>> Feature_1 Feature_2 Target
0 70.043712 84.418664 0.0
1 67.651434 72.785806 1.0
2 95.145796 1.270320 2.0
3 41.358770 4.881279 3.0
4 9.992856 50.806631 4.0
5 20.024754 74.415417 5.0
6 19.289200 70.084475 6.0
7 29.322811 77.447945 7.0
8 0.510884 11.285765 8.0
9 11.095367 24.766823 9.0
10 2.323630 72.732115 10.0
11 34.003494 19.750316 11.0
12 90.917959 97.834699 12.0
13 53.280254 25.913185 13.0
14 58.381262 32.569065 14.0
# init base knn
model = baseKNN(k=3, metric="euclidean")
# fit model
X_train = sample_df.drop(columns="Target", axis=0)
y_train = sample_df["Target"]
model.fit(X_train, y_train)
# set test point
test_point = np.array([[60, 14]])
# find nearest neighbors
nearest_neighbors, nearest_neighbors_distances = model._get_nearest_neighbors(test_point)
display(print(f"calculated nearest distance: {nearest_neighbors_distances}"),
print(f"labels of the nearest neighbors: {nearest_neighbors}"))
>>> calculated nearest distance: [13.67768095 18.63948763 20.75202463]
>>> labels of the nearest neighbors: [13. 14. 3.]
Di tahap ini, kita mengadaptasi proses untuk menggunakan Pandas DataFrame, yang lebih umum digunakan dalam proyek-proyek data science. Kita menggunakan dua kolom feature dari DataFrame sample_df sebagai X_train dan 1 kolom target sebagai y_train. Di proses ini, kita menguji bagaima model KNN kita dapat bekerja dengan tipe data yang berbeda dan menunjukkan fleksibilitas untuk implementasi kita kedepannya.
Pengujian regressionKNN
# generate sample data
np.random.seed(666)
X_train = np.random.rand(15, 2) * 100 # 15 rows, 2 kolom
y_train = np.arange(15)
# build dataframe
data = np.hstack((X_train, y_train.reshape(-1, 1))) # combine x dan y secara horizontal
sample_df = pd.DataFrame(data, columns=["Feature_1", "Feature_2", "Target"])
# display dataframe
sample_df.head()
>>> Feature_1 Feature_2 Target
0 70.043712 84.418664 0.0
1 67.651434 72.785806 1.0
2 95.145796 1.270320 2.0
3 41.358770 4.881279 3.0
4 9.992856 50.806631 4.0
# init regression knn
model = regressionKNN(k=3, metric="euclidean")
# fit model
X_train = sample_df.drop(columns="Target", axis=0)
y_train = sample_df["Target"]
model.fit(X_train, y_train)
# set test point
test_point = np.array([[70, 70]])
# predict
prediction, nearest_neighbors, nearest_neighbors_distances = model.predict(test_point)
display(print(f"prediction: {prediction}"),
print(f"nearest neighbors: {nearest_neighbors}"),
print(f"calculated nearest distance: {nearest_neighbors_distances}"))
>>> prediction: [4.33333333]
>>> nearest neighbors: [ 1. 0. 12.]
>>> calculated nearest distance: [ 3.64369012 14.41873054 34.81855053]
Oke, selanjutnya kita juga menguji implementasi regressionKNN untuk melihat bagaimana model bisa digunakan untuk kasus regresi. Masih dengan menggunakan dataset dummy yang kita generate menggunakan NumPy, kita mencoba untuk memprediksi nilai target berdasarkan rata-rata nilai dari tetangga terdekatnya. Jadi, untuk data point test kita dengan nilai 70 pada kedua featurenya, tiga tertangga terdekatnya adalah 1, 0, dan 12, sehingga nilai rata-rata target kita adalah 4.333. Terlihat sudah cukup sepertinya untuk kasus-kasus regresi sederhana.
Pengujian classficationKNN
np.random.seed(555)
n_samples = 15
feature1_class0 = np.random.uniform(1, 20, n_samples)
feature2_class0 = np.random.uniform(5, 20, n_samples)
y_class0 = np.zeros(n_samples)
feature1_class1 = np.random.uniform(18, 30, n_samples)
feature2_class1 = np.random.uniform(22, 35, n_samples)
y_class1 = np.ones(n_samples)
X_train = np.vstack((np.column_stack((feature1_class0, feature2_class0)),
np.column_stack((feature1_class1, feature2_class1))))
y_train = np.hstack((y_class0, y_class1))
sample_df = pd.DataFrame(X_train, columns=["Feature_1", "Feature_2"])
sample_df["Target"] = y_train
test_point = np.array([[19, 19]])
sample_df.head(10)
>>> Feature_1 Feature_2 Target
0 14.638848 13.167030 0.0
1 1.909248 5.617921 0.0
2 18.944968 12.022494 0.0
3 14.041221 18.331201 0.0
4 12.042939 12.143878 0.0
5 3.710894 11.187335 0.0
6 18.972464 14.241598 0.0
7 7.459821 9.821248 0.0
8 12.788274 13.713039 0.0
9 9.606233 10.949211 0.0
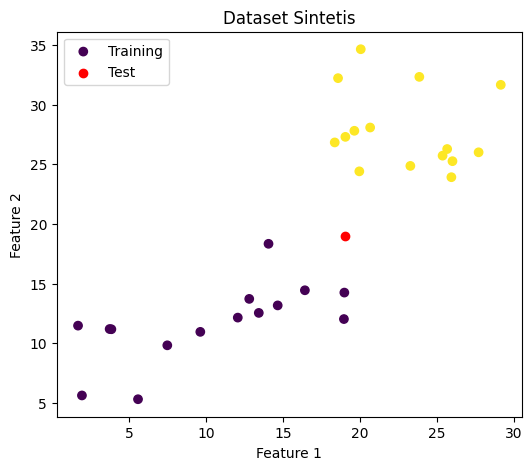
plt.figure(figsize=(6,5))
plt.scatter(sample_df["Feature_1"], sample_df["Feature_2"], c=sample_df["Target"], label="Training")
plt.scatter(test_point[0][0], test_point[0][1], color="red", label="Test", zorder=5)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("Dataset Sintetis")
plt.legend()
plt.show()
>>>
# init classification knn
model = classificationKNN(k=7, metric="euclidean")
# fit model
X_train = sample_df.drop(columns="Target", axis=0)
y_train = sample_df["Target"]
model.fit(X_train, y_train)
# predict
prediction = model.predict(test_point)
print(f"prediction: {prediction}")
>>> prediction: [{'class': 0.0, 'probability': 0.7142857142857143}]
Ini adalah tahap terakhir dari pengujian awal kita, yaitu menguji classficationKNN apakah sudah sesuai dengan ekspektasi kita untuk menyelesaikan kasus klasifikasi. Dalam pengujian ini, kita menggunakan dataset dummy yang memiliki dua kelas berbeda; 0 dan 1. Dengan menggunakan euclidean sebagai metrik pengukuran jaraknya dan 7 sebagai jumlah tetangga terdekat yang ingin dilihat, kita mendapatkan bahwa test point kita dengan nilai 19 pada kedua featurenya diprediksi sebagai kelas 0 dengan skor probabilitas sebesar 0.714.
Meskipun apa yang sudah kita tulis sudah cukup mengimplementasikan fungsi-fungsi esensial dari KNN, rasanya masih banyak opportunities untuk kita dapat melakukan improvement dari program kita ini, seperti optimisasi performanya (misal menambahkan opsi untuk implementasi dimensionality reduction), menambahkan lebih banyak metrik-metrik di luar tiga metrik yang sudah kita tetapkan, atau juga bisa menambahkan opsi untuk menghandle fitur-fitur kategorikal yang tentunya nanti akan ada di dalam dataset kita jika nantinya program ini akan kita gunakan untuk menyelesaikan real use-case.
Overall, marilah kita merasa cukup lebih dulu saat ini karena setidaknya kita sudah mendapat sebuah milestone; mendemostrasikan dan mengimplementasikan bagaimana KNN bekerja untuk membantu dapat membantu kita menyelesaikan kasus-kasus regresi maupun klasifikasi dengan machine learning.
Mungkin pada artikel selanjutnya, kita akan mengembangkan proyek ini menjadi lebih lengkap dan juga mengimplementasikannya ke dalam dataset yang bukan lagi dummy.
Artikel ini merupakan bagian awal dari rangkaian proyek saya dalam mengimplementasikan dan menulis algoritma machine learning dari (hampir) awal. Materi dan pendekatan yang digunakan berasal dari kelas Advance Machine Learning di Sekolah Data Pacmann.
Silahkan kunjungi laman LinkedIn untuk bisa berkoneksi ataupun berkomunikasi lebih lanjut.