
Tulisan ini adalah seri kedua dari rangkaian proyek mengimplementasikan dan menulis algoritma machine learning (hampir) dari awal. Tulisan pertama dari seri ini adalah Build a Simple K-Nearest Neighbor Algorithm (Almost) from Scratch. Pada tulisan kali ini, kita akan coba fokus untuk membangun algoritma model linear regression.
Sama seperti KNN, linear regression adalah salah satu algoritma supervised learning yang paling dasar, dimana algoritma ini digunakan untuk memprediksi nilai output kontinyu berdasarkan satu atau lebih nilai input. Prinsip dasarnya cukup sederhana, yaitu mencari hubungan linear antara variabel independen (input) dan variabel dependen (output).
Adapun linear regression akan bekerja berdasarkan persamaan linear berikut:
dimana:
- y adalah variabel dependen atau nilai yang ingin kitap prediksi,
- Xi adalah variabel independen,
- βi adalah koefisien untuk variabel independen,
- β0 adalah intercept.
Nah, di dalam kontek algoritma linear regression kita nanti, kita akan mencari nilai β yang meminimalkan residual sum of squares (RSS), yaitu varians error dari output prediksi model kita. Source code untuk algoritma linear regression kita akan kita tulis di dalam base.py yang ada di dalam direktori linear.
ml_from_scratch/
├── neighbors
├── linear/
│ ├── __init__.py
│ └── base.py
Nantinya, di dalam direktori ini kita juga akan menyimpan beberapa source code dari pengembangan base model kita, seperti regularisasi dan logistic regression. Namun untuk sekarang, kita hanya akan fokus ke base model lebih dulu. Sudah siap? Mari kita mulai!
Pseudocode Base Model
Sebelum menulis source code untuk algoritma base linear regression kita, salah satu best practice yang direkomendasikan banyak orang adalah menulis pseudocode kita lebih dulu. Berdasarkan pemahaman mengenai linear regression, kita dapat menulis pseudocode untuk kelas kita nantinya kurang lebih seperti berikut:
baseLinearRegression:
Fungsi __init__(self, fit_intercept=True):
Inisialisasi intercept dan koefisien
Tentukan apakah model harus mencakup intercept atau tidak
Fungsi fit(self, X, y):
Ubah X dan y menjadi array numpy jika belum
Jika fit_intercept == True, maka kita akan tambahkan kolom ones ke X
Hitung koefisien
Pisahkan intercept dari koefisien jika fit_intercept True
Fungsi predict(self, X):
Hitung prediksi y menggunakan model linier
Nah, setelah kita menyusun pseudocode seperti di atas, kita dapat pelan-pelan membangun kelas kita untuk algoritma linear regression ini.
Implementasi dari Pseudocode
Setelah memahami dan melalui beberapa kali iterasi, kita dapat menerjemahkan pseudocode kita ke dalam sebuah kelas dengan menggunakan Python seperti berikut ini:
import numpy as np
import pandas as pd
class baseLinearRegression:
def __init__(self, fit_intercept=True):
# inisialisasi setup
self.coef_ = None
self.intercept = None
self.fit_intercept = fit_intercept
# *************************************
def fit(self, X, y):
# handling different data type input
if isinstance(X, pd.DataFrame):
X = X.values
else:
X = np.array(X)
if isinstance(y, pd.Series):
y = y.values
else:
y = np.array(y)
# buat design matrix A
if self.fit_intercept:
A = np.c_[np.ones((X.shape[0], 1)), X]
else:
A = X
# hitung optimal coefficients
theta = np.linalg.inv(A.T @ A) @ A.T @ y
# extract parameter
if self.fit_intercept:
self.intercept = theta[0]
self.coef_ = theta[1:]
else:
self.intercept = 0.0
self.coef_ = theta
# *************************************
def predict(self, X):
# handling different data type input
if isinstance(X, pd.DataFrame):
X = X.values
else:
X = np.array(X)
y_pred = np.dot(X, self.coef_) + self.intercept
return y_pred
Dengan pengimplementasian ini, kita setidaknya sudah dapat memodelkan hubungan antara variabel independen dan dependen serta melakukan prediksi ketika terdapat data point baru. Selanjutnya, kita akan menguji kelas ini dengan kasus regresi sederhana.
Pengujian baseLinearRegression
Pada bagian ini kita akan coba menguji baseLinearRegression yang telah kita tulis sebelumnya. Kita akan menggenerate dataset linear sederhana untuk melihat apakah model kita sudah cukup memenuhi ekspektasi kita untuk dapat memodelkan hubungan linear antar feature dan target variable.
np.random.seed(42)
# generate random data
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
plt.figure(figsize=(6,5))
plt.scatter(X, y)
plt.xlabel('Feature')
plt.ylabel('Target')
plt.title('Dummy Linear Dataset')
plt.show()
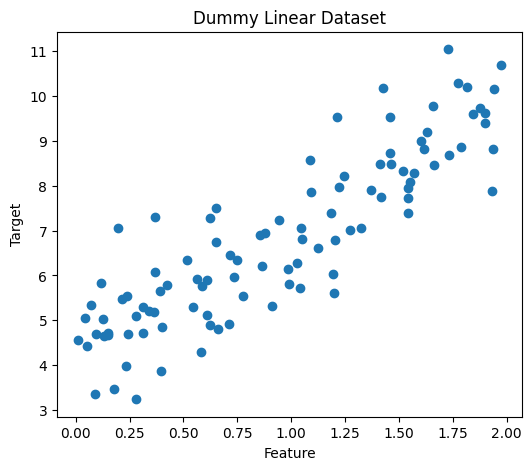
Setelah kita mempunyai dataset di atas, kita bisa mencoba menggunakan baseLinearRegression dan fit model ini ke dataset yang kita punya dan juga membuat prediksi ke data point baru atau data eksisting kita.
model = baseLinearRegression()
model.fit(X, y)
# generate test data untuk prediksi
X_test = np.linspace(X.min(), X.max(), 100).reshape(-1, 1)
y_pred = model.predict(X_test)
# plot original data dan hasil model
plt.figure(figsize=(6,5))
plt.scatter(X, y, label='Original data')
plt.plot(X_test, y_pred, color='red', label='Fitted line')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.title('baseLinearRegression Model Fit')
plt.legend()
plt.show()
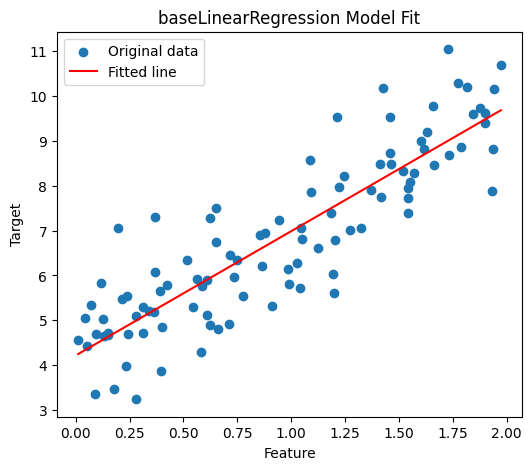
Dengan memvisualisasikan hasil prediksi model kita, kita dapat melihat seberapa fit line prediksi kita terhadap data point yang ada. Selain dengan memvisualisasikannya, tentu kita juga dapat menggunakan beberapa metrik seperti mean squared error atau MSE untuk mengevaluasi performa dari model tersebut dengan membandingan nilai prediksi dengan nilai aktual target.
Meskipun cukup sederhana, dengan menulis dan mengimplementasikan sendiri linear regression seperti di atas, harapannya adalah kita dapat memiliki pemahaman yang lebih dalam lagi bagaimana model bekerja dan bagaimana bisa diaplikasikan ke dalam berbagai kasus yang lebih kompleks.
Silahkan kunjungi laman LinkedIn untuk bisa berkoneksi ataupun berkomunikasi lebih lanjut.